0x01 古早时期的 NVIDIA CUDA 开发套件
笔者在一次偶然间于海鲜市场上发现了一套诡异的开发板-- NVIDIA CARMA, 搜索了一下发现居然是非常稀有的 NVIDIA 早期黑历史(划掉)用于在 ARM 平台上进行 CUDA 开发的设备,于是入手了这块奇特的小板子。
收到快递的那一刻我简直想骂娘,因为卖家居然直接用 CARMA 的外包装邮寄过来而完全没有套箱子,导致这稀有的箱说全的整套开发板箱子已经不算完整了。

打开箱子就是开发板本体和一张说明书了,电源可能是被卖家单独拆出来卖掉了吧所以并没有附带。怀着忐忑的心情将其擦电揩机,屏幕居然出乎意料得直接点亮,进入了 NVIDIA 定制的 Ubuntu Linux 系统内。


他甚至有直到现在都长成这样的 nvidia-settings!(划掉)
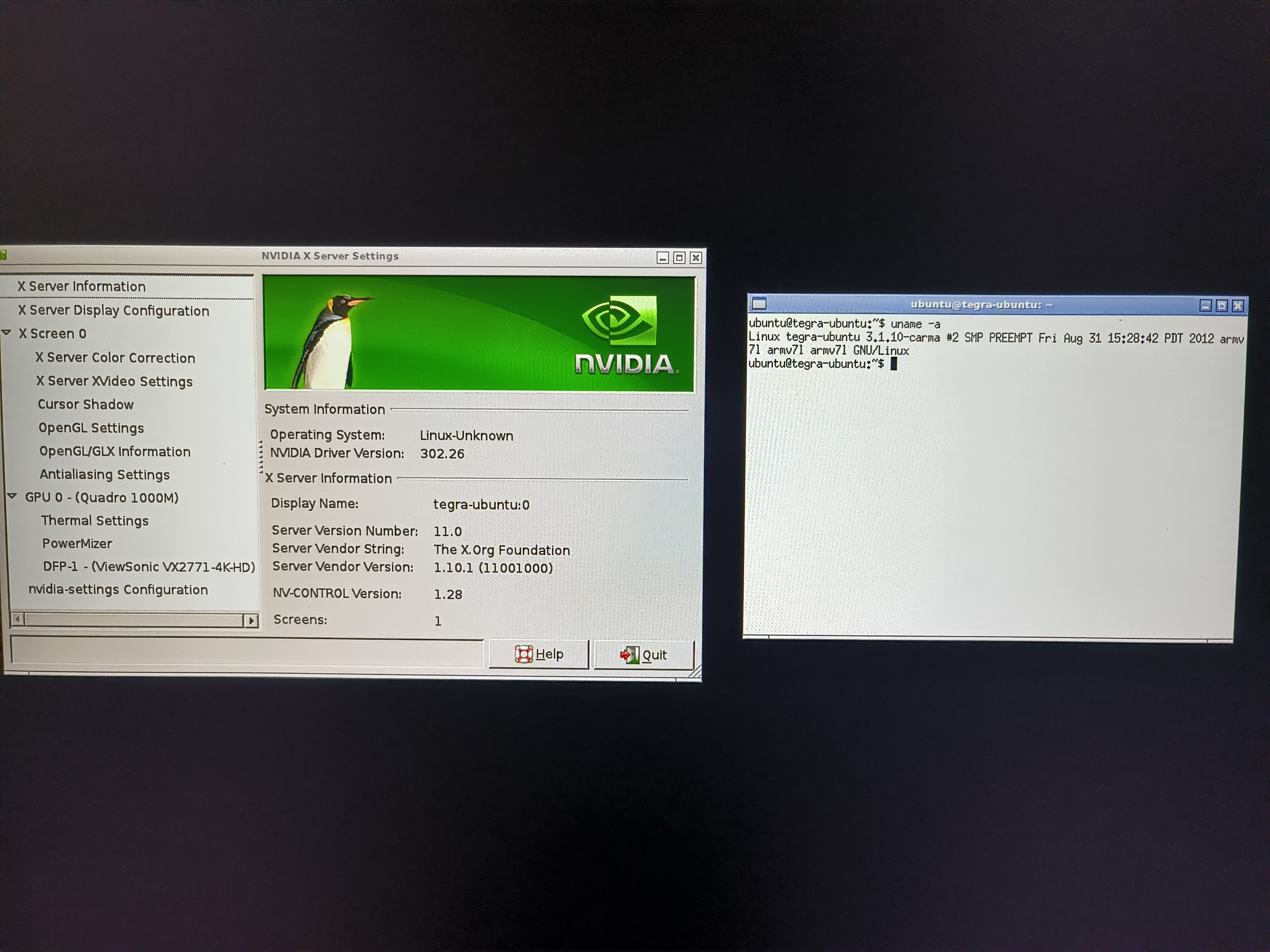
可以看到这块板子的配置是 Tegra 3 SoC 配和一块 Quardo 1000M 显卡,配备有 2GiB 大小的 LPDDR3 与 4GiB 大小的 EMMC。
查询更多信息看到了很有意思的事情。ARM 指令集架构在很久以前就被打上了“能耗比高”的标签,于是就有了 NVIDIA 在 ARM HPC 领域初次的尝试。1

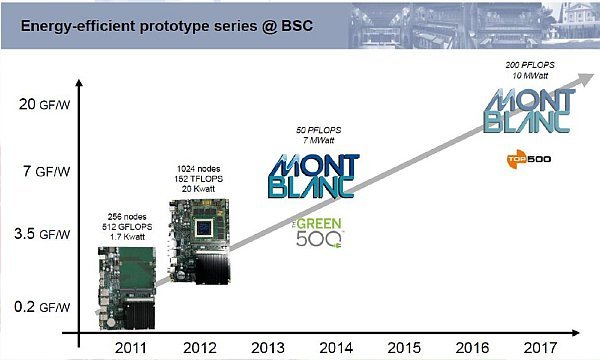
Carma Devkit源于NVIDIA的Project Carma,其实Seco出售的Carma套件就是NVIDIA提供的,通过ARM处理器加Quadro芯片的形式组成一个加速卡,具体来说就Tegra 3处理器搭配Qyadro 1000M加速卡。 E4的每个计算机簇由8块Carma组成,使用520W电源,最大计算能力为2.16TFLOPS(8个Quadro 1000M),尚不足一块Tesla K20X计算能力的一半,因为Quadro 1000M只有96个CUDA核心,270GFLOPS的浮点运算能力,而且搭配的CUDA 2.1只支持单精度运算,不具备FP64双精度运算能力。 E4提供的HPC阵列由12个节点组成,每个节点搭配一块Carmar主板和2个Quadro 1000M加速卡,总计算能力为6.48TFLOPS,搭配1500W电源。另外,E4还提供纯粹由Tegra 3处理器组成的加速卡,每个主板有48个Tgera 3核心,总计192个ARM内核,只要搭配400W电源就行了。
而欧盟也意欲将其作为真正的超算来使用。
0x02 点亮,把玩
系统 dmesg 信息
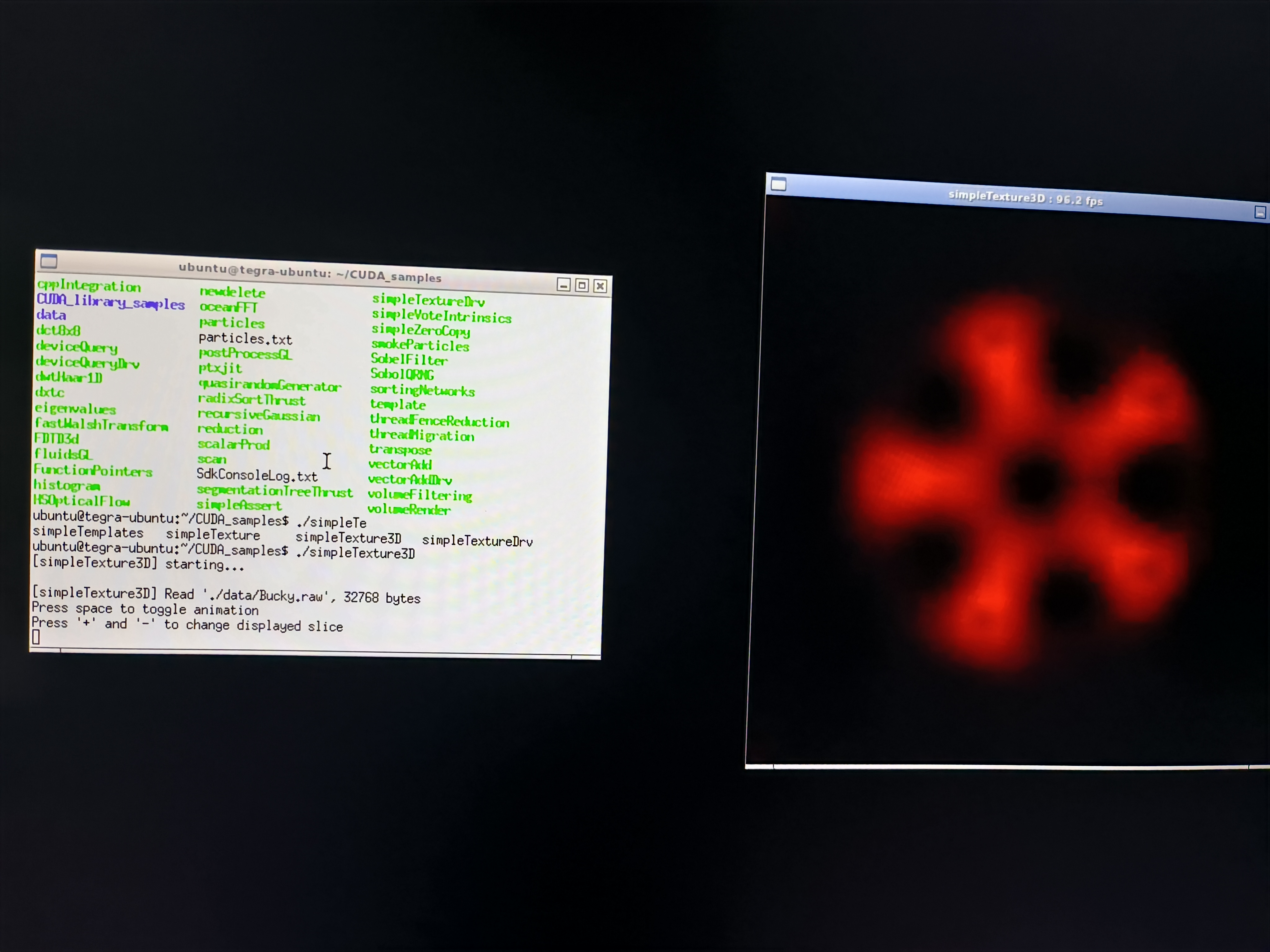
翻阅了一下系统文件,发现前一任机主甚至没有动任何文件,完整的 CUDA for armv7 的 demo 就在文件夹中安静的躺着。很可能这台机器并没有被使用,而是被丢到了一个角落直到某个海鲜市场商家捡到了它。
运行机内的 demo 过程很顺畅。
而给奇奇怪怪的设备跑分作为笔者的习惯之一,自然它也不能幸免。第一次跑 coremark 使用了机器内自带的老旧 gcc 4.5.2 编译器,而后又静态编译了一个 gcc 11.2.1的版本。
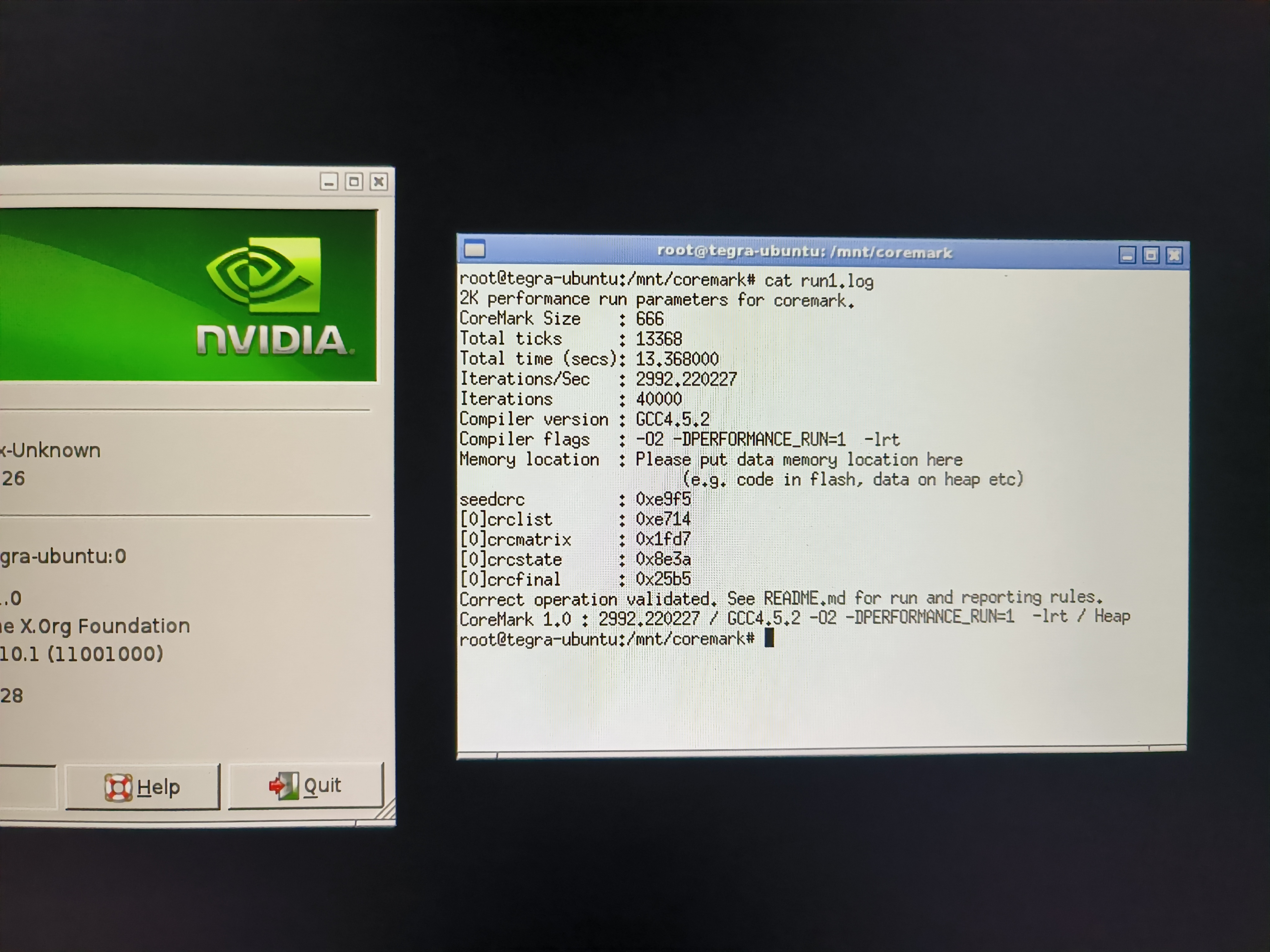
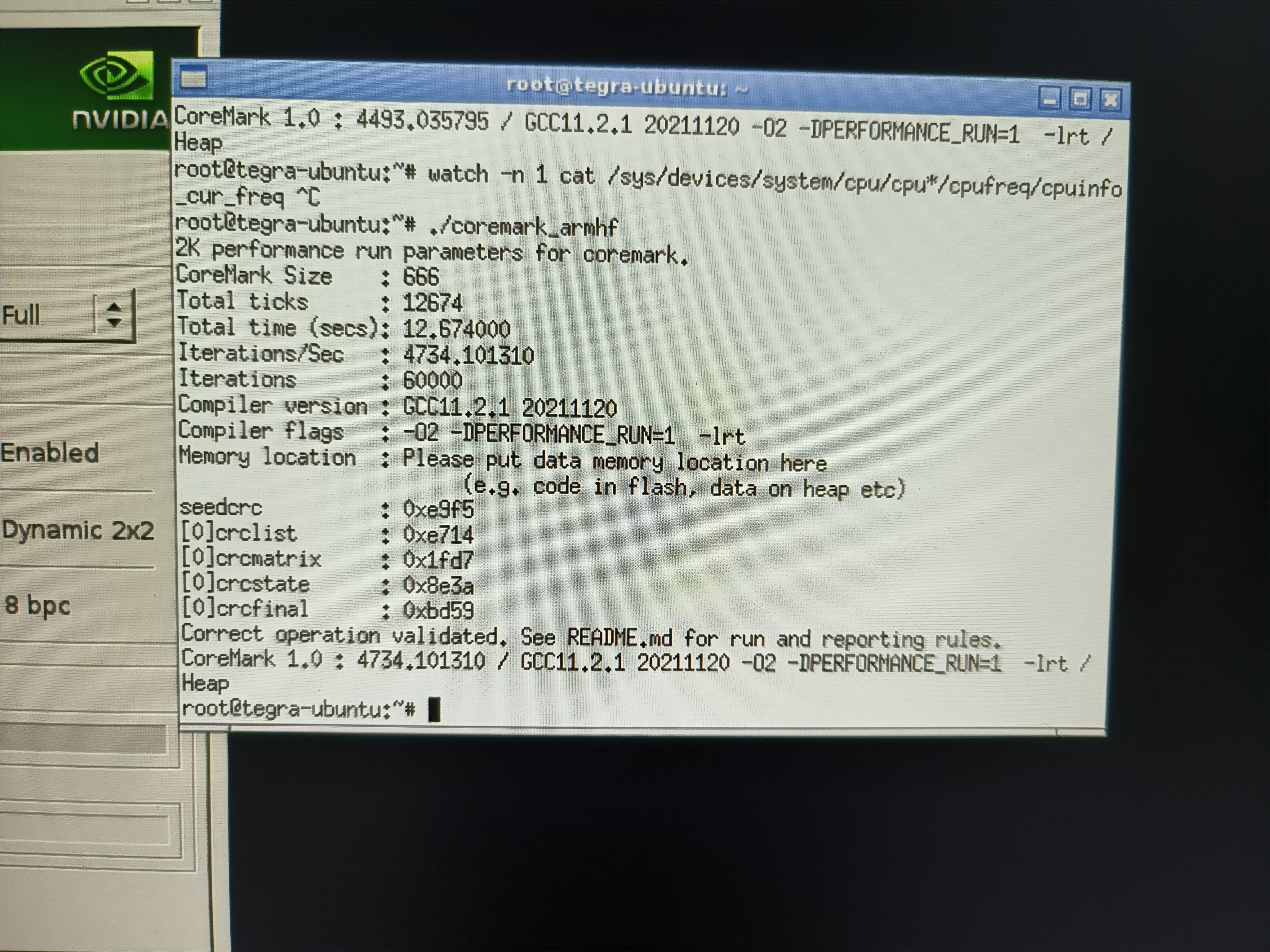
在把玩一段时间之后,我意识到了这台机器的稀有性,于是将其 EMMC 全盘 dump 出来做了备份。
0x03 AGX Orin 的捡垃圾之旅
后来笔者在机缘巧合之下收到了一块由某自动驾驶车机拆机的 AGX Orin 模块。作为需要承载自动驾驶人物的核心计算设备,它的性能与前者相比可以说是巨大飞跃了。而 Orin SoC 的统一内存让他有很大的显存,足够跑一些最新最热开源 LLM 了。

然而笔者还是太 naive 了,兴许是中奖的缘故,笔者这台机器并不能够稳定地工作。只要 CPU 与 GPU 同时有负载下就会报错死机重启,而笔者也并没有找到解决方法。
不过让人感到意外的是,虽然并没有苹果系 ARM CPU 为转译进行的优化,但其搭载的 Cortex A78AE 核心却可以跑得了 Rosetta2,甚至在 coremark 这种简单的测试场景下表现还很不错。
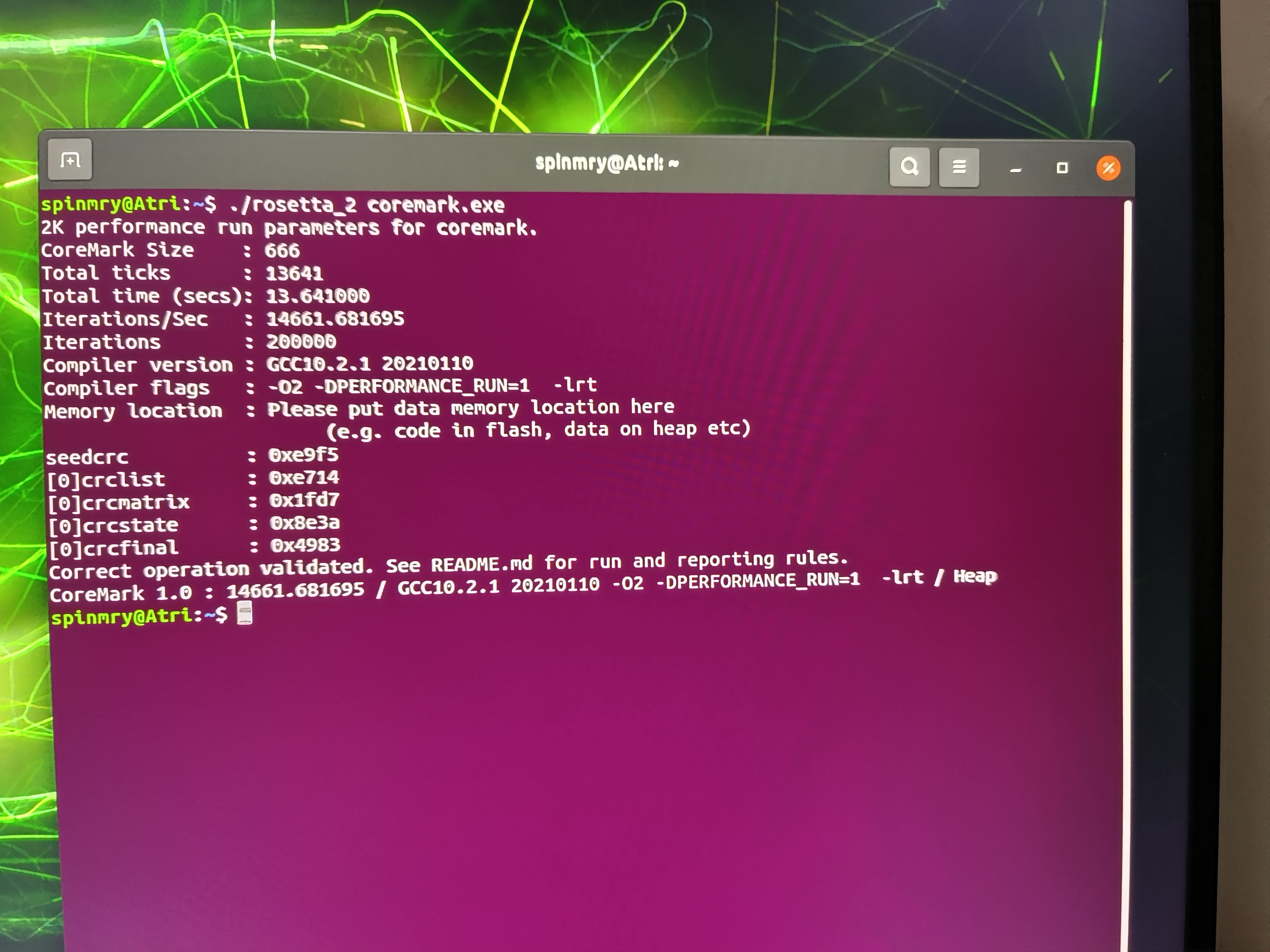
作为参考 AGX Orin 原生情况下的 coremark 跑分为 18954。此事在笔者的野鸡 coremark 跑分榜单中亦有记载(错乱)
0x04 结语
从 2012 年到 2024 年的今天,NVIDIA 仍在向着提高计算能耗比做着努力,而其也并未间断地投入大量资源发展 ARM 下的 CUDA 生态。从车机芯片到超算芯片,NVIDIA 定制的 ARM 指令集架构的处理器似乎无处不在。从 CARMA 到 GB200 可能这就是一种历史的传承罢。(发癫时间:笔者好想摸摸 GB200 啊)